
For my specialization project I decided to create an Archive File format based on what I learned from Casey Muratori’s Handmade Hero series.
Unlike the file format Casey makes I decided to store all of the meta data in a json string located at a specific place in the file, as described in the header. The largest reason for this change was that we already used .meta files for each asset file that were in the json format, so doing it this way would make integration much easier. I also has the added benefit of allowing things to be added to the meta data without knowledge of the archive format.
When loading a specific asset from the archive we only need to know two things, offset and size, unless we add support for multiple archive files, in which case we need to know which file to load from. I decided to store the assets in a 16 byte aligned sequence with no set order. The 16 byte alignment was something I added with the hope that we could use memory mapped file or allocate and read multiple assets in one go without having to worry about the alignment of the actual data stored in the asset.
No that I had the basic format I wanted it was time to write a POC version.

The file header only really needs the first four fields to be to work, but I decided to add the rest to be able to debug the file more easily.
I am more comfortable with C style programing and this code is not something that will run outside of the build pipeline, so much of the code is very ad hoc.

I start by creating the header and filling it with the data know at the start, then I skip the size of the header.
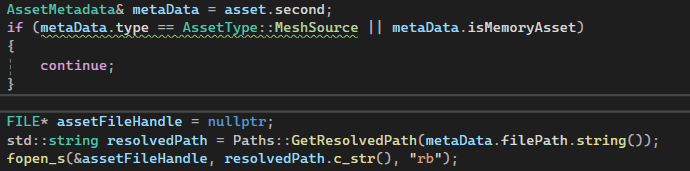
While looping through all of the assets we have I skip MeshSource (FBX) as they are never used outside of the editor, and MemoryAssets as they are defined in code and have not asset file.
Then for each file I get the file size and then the aligned file size before checking if we need to grow our read buffer and reading the entire file.

Before writing the asset to the archive file I make sure that the padding is zeroed to make it easier to catch mistakes in the future. Then I write all of the metadata and move the assetOffset by the aligned size.

After all of the assets have been written to the archive file we now know the rest of the information needed for the header. So we write the json string to the current offset and then move back to the start to write the header.
And there we have it, a functional asset packer. Now we only need start reading from it.
Reading from the file can be split in to two categories, mounting and streaming.
Mounting is the act of reading the header, verifying the that it is the correct format and version, and then reading the metadata to populate the asset table. For this I used memory mapped to get the data in to memory as fast as possible single threaded. Here I ran into the problem of memory mappings needing to be aligned to the allocation granularity I and I started to re-evaluate me initial thought of using mapping each asset into memory separately.
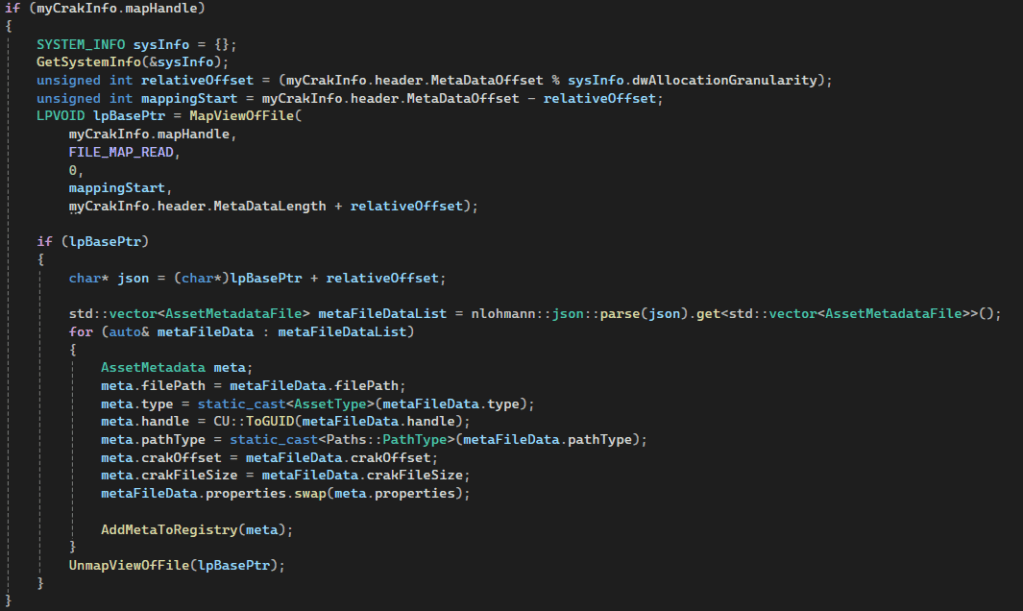
Streaming is the act of loading and unloading specific assets from the archive on multiple threads.
I was not able to finish the streaming part, but I have decided that I will used overlapped I/O when I actual complete this project. Then I will change the existing asset loading to use the metadata instead of just the file path and then have a generic load asset method that takes the metadata, checks if it is in the archive or not, and then loads the asset from the appropriate place. Only this part of the code base will have any distinction between the two.
On a final note, this was a really fun challenge for me and I want to complete it and refine it some day.
